[Java]컬렉션(Collections) 정리
- study
- 2021. 12. 2. 20:56
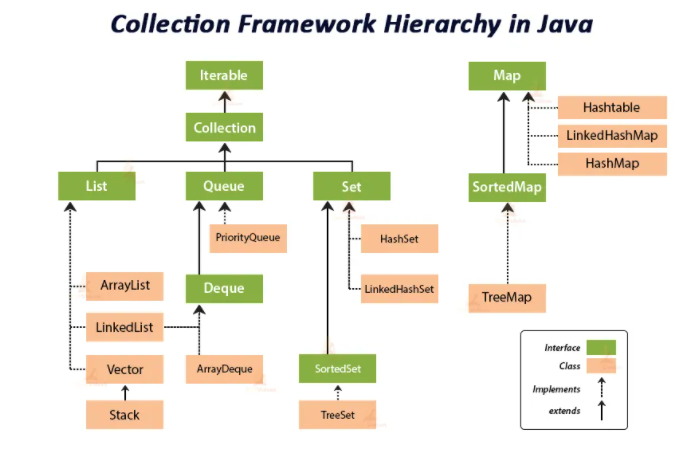
컬렉션 프레임워크 란?
- 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미한다.
- 자료구조와 알고리즘을 구조화 하여 클래스로 구현해 놓은 것
| 구분 | 종류 | 중복 허용 | 순서 존재 | 정렬 여부 | THREAD-SAFE |
| LIST | ArrayList | O | O | X | X |
| LinkedList | O | O | X | X | |
| Vector | O | O | X | O | |
| SET | HashSet | X | X | X | X |
| Linked HashSet |
X | O | X | X | |
| TreeSet | X | X | O | X | |
| MAP | HashMap | X | X | X | X |
| Linked HashMap |
X | O | X | X | |
| Hashtable | X | X | X | O | |
| TreeMap | X | X | O | X |
List는 중복이 가능하고, 순서가 있는 데이터의 집합이다.
- ArrayList - 특정 원소 조회가 많은 경우 사용하는 것이 좋다.
- 배열을 이용하여 만든 리스트
- 기본 크기는 10이지만 원소가 늘어나면 더 큰 배열에 옮긴다.
- 인덱스로 조회가 가능하므로, 인덱스만 알면 해당 데이터를 빠르게 조회 할 수 있다.
- 삽입, 삭제를 하면 그 뒤에 있는 데이터를 뒤로 밀거나 앞으로 당겨야 하기 때문에 느리다. (O(N))
- LinkedList - 조회보다 삽입/삭제가 많은 경우에 사용하는 것이 좋다.
- 노드와 포인터를 이용하여 만든 리스트이다.
- 특정 원소를 조회하는 경우 첫 노드 부터 순회해야 하기 때문에 ArrayList에 비해 느리다.
- 포인터로 각각 노드들을 연결하고 있어서, 삽입/삭제가 빠르다.
- 단순히 기존 포인터를 끊고 새로운 노드에 연결하면 되기 때문이다.
- 그러나 중간에 데이터를 삽입, 삭제 할 경우 그 데이터까지 순차적으로 조회해야 하기 때문에 O(N)의 시간복잡도를 가진다.
- Vector - ArrayList와 비슷하게 배열로 만들어진 리스트지만, thread-safe하다.
- 한번에 하나의 스레드만 접근이 가능하다.
- get, put에 모두 syncronized가 걸려있어서 스레드마다 lock이 걸리게 되고, 성능이 ArrayList보다 좋지 않다.
- Stack - LIFO(Last-In-First-Out)특성을 가지는 자료구조이다.
- 마지막에 들어온 원소가 처음으로 나가는 특징을 가진다.
- 들어올 때는 push, 나갈때는 pop이라는 용어를 사용한다.
Set은 중복이 불가능하고, 순서가 없는 데이터의 집합이다.
- HashSet - 중복을 허용하지 않고, 순서를 가지지 않는다.
- HashSet이 판단하는 동일한 객체란 꼭 같은 인스턴스를 뜻하지 않는다. (동일성)
- HashSet은 객체를 저장하기 전에 먼저 객체의 hashCode() 메소드를 호출한다. 그리고 같다면 equals()로 두 객체리를 비교해서 동등성을 판단한다.
@Test
public void hashSetTest() {
Set<String> hashSet = new HashSet<>();
hashSet.add("하나");
hashSet.add("둘");
hashSet.add("셋");
System.out.println(hashSet);
hashSet.add("넷");
hashSet.add("다섯");
System.out.println(hashSet);
}
- LinkedHashSet - 중복은 허용하지 않지만, 순서를 가진다.
@Test
public void linkedHashSetTest() {
Set<String> hashSet = new LinkedHashSet<>();
hashSet.add("하나");
hashSet.add("둘");
hashSet.add("셋");
System.out.println(hashSet);
hashSet.add("넷");
hashSet.add("다섯");
System.out.println(hashSet);
}
- TreeSet - 중복은 허용하지않고, 순서를 가지지 않는다. 그러나 정렬이 되어있다.
- 이진트리를 기반으로 한 Set컬렉션이다.
@Test
public void treeSetTest() {
Set<String> hashSet = new TreeSet<>();
hashSet.add("하나");
hashSet.add("둘");
hashSet.add("셋");
System.out.println(hashSet);
hashSet.add("넷");
hashSet.add("다섯");
System.out.println(hashSet);
}
Queue는 FIFO(First-In-First-Out)구조를 가진다.
- 처음 들어온 원소가 처음으로 나간다는 특징이 있다.
- 들어올때는 enqueue, 나갈때는 dequeue라고 한다.
- PriorityQueue는 우선순위를 가지는 큐로 원소에 우선순위를 부여하여 높은 순으로 먼저 반환한다.
- Dequeue는 양쪽으로 넣고 빼는 것이 가능한 큐 자료구조 이다.
Map은 키와 값을 가지고 순서는 기억하지 않으며 키는 중복이 불가능하고, 값은 중복이 가능한 데이터 집합이다.
- HashMap은 키와 값을 가지고, 순서는 기억하지 않으며 키는 중복이 불가능하고, 값은 중복이 가능하다.
- key와 value에 null을 허용한다.
- 동기화를 보장하지 않는다.
@Test
public void hashMapTest() {
Map<String, String> hashMap = new HashMap();
hashMap.put("사과", "apple");
hashMap.put("포도", "grape");
hashMap.put("수박", "watermelon");
hashMap.put("배", "pear");
System.out.println(hashMap);
}
- HashTable은 HashMap과 동일한 특징을 가지지만 Thread-Safe하여 동기화를 지원한다.
- key와 value에 null을 허용하지 않는다.
- 동기화를 보장한다.
- get(), put(), remove() 등에 syncronized 키워드가 붙어있다.
- LinkedHashMap은 들어온 순서대로 순서를 가지는 Map이다.
@Test
public void linkedHashMapTest() {
Map<String, String> hashMap = new LinkedHashMap<>();
hashMap.put("사과", "apple");
hashMap.put("포도", "grape");
hashMap.put("수박", "watermelon");
hashMap.put("배", "pear");
System.out.println(hashMap);
}
- TreeMap은 key를 기준으로 정렬이 되어 저장되는 Map이다.
- 이진트리를 기반으로한 Map이다.
- 부모 키값을 비교하여 낮은 건 왼쪽에 높은건 오른쪽에 Map.Entry를 저장한다.
- 그래서 저장시간이 다른 자료구조에 비해 오래 걸린다.
- 이진트리를 기반으로한 Map이다.
@Test
public void treeMapTest() {
Map<String, String> hashMap = new TreeMap<>();
hashMap.put("사과", "apple");
hashMap.put("포도", "grape");
hashMap.put("수박", "watermelon");
hashMap.put("배", "pear");
System.out.println(hashMap);
}
'study' 카테고리의 다른 글
| Spring AOP - Transactional, Async (0) | 2022.03.25 |
|---|---|
| [Java]LocalDateTime, OffsetDateTime, ZonedDateTime, Instant (0) | 2022.03.16 |
| [Spring]프로토타입과 스코프 (0) | 2021.12.02 |
| [DB]트랜잭션 정리 (0) | 2021.12.02 |
| [Spring] Scheduling - CronTask (0) | 2021.10.02 |